I feel like a lot of breakdowns on AI go very heavy on the awe and light on the practical understanding of how these systems work. While its really cool, it isn’t magic. It is also comforting and helpful to look at AI for what it is.

One area I’m particularly interested in for an upcoming post (and project) is reinforcement learning. I had read a book about evolutionary systems (this one) in the 2000s, but I have had little practical exposure recently. I sat down with ChatGPT and asked it to create a market simulation with 5 commodities. What it spit out was kind of half baked. To be fair it was a big ask, so I asked for a simple example of reinforcement learning and it was in the zone!
It created this python program, where the agent uses Q learning. The way Q learning works is it keeps track of an environment, actions, and rewards. People have likened this to how animals learn or how children learn. This particular program is all about navigating a small grid, and its goal is to reach the end of the grid.
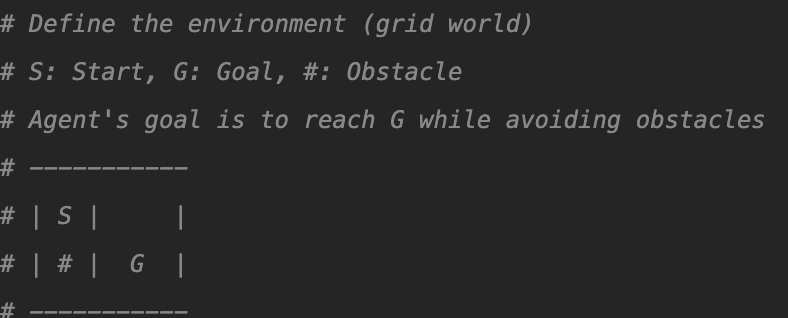
The env up top is a representation of the S to G grid, but as two arrays within a larger array, to represent each space. I think ChatGPT’s ASCI representation looks more like 2×2, but alas.
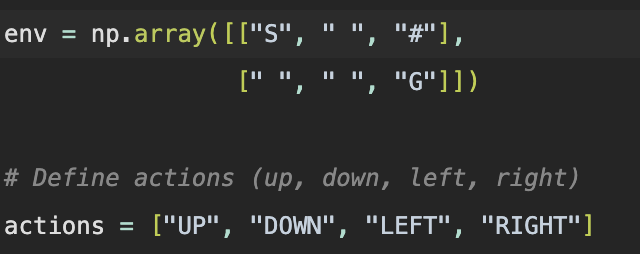
The actions are pretty simple. Up, down, left, and right. It reminds me of Boebot, a BASIC powered robot we had in school. Amazingly, the agent is much more powerful than Boebot on its best day, because it can learn. Like the terminator.

me and a Boebot, 2007
Unlike the terminator, its brain is not futuristic at all, in fact its just a table tracking rewards based on State and Action combinations. Now this is the heart of the matter, because at the end of the program it pumps out the Q table, which is underwhelming.

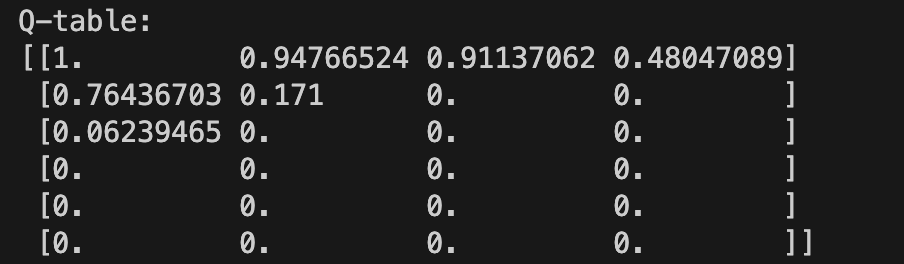
This representation is not great at letting us know whats happening. I understand that each place in the Q table is a state-action and each number is a reward rating, but what does that really mean.
I changed the program to print out the final Q table but in a more obvious format, for ease of really seeing whats going on. I had it print out the state + action with the reward, in a list. I also had it name each space in the grid so that there wouldn’t be blank spaces in the list, since we’d have no grid for reference.
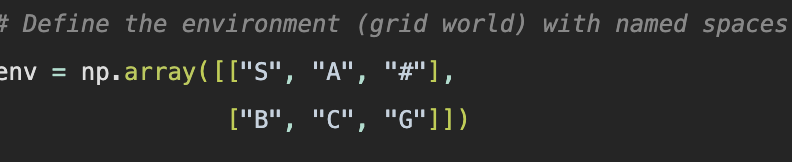
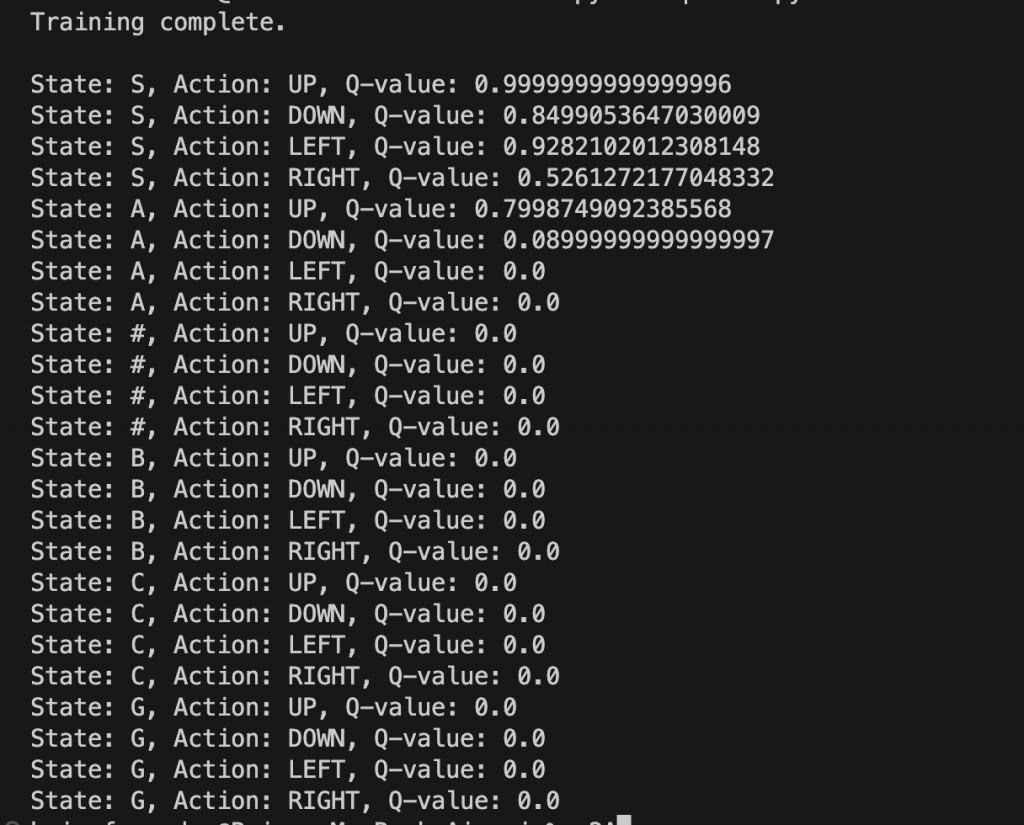
What is interesting is you can completely see how this works, but also I noticed its broken. This simple example doesn’t actually learn well and ChatGPT agrees that it probably needs adjustment. Looking at the Q table I never would have guessed.
How this should work is the agent should use the Q table as sort of a map for its decisions, a history of “I did x and got y”, or here “I went up from S and it was great!” I like to think of it as a person spelunking through a cave, drawing maps as they hit dead ends and back track. The Q table is essentially that, its updated as each evolution happens.
Here is the updated program.
Leave a Reply